https://blog.tensorflowcn.cn/2020/03/exploring-helpful-uses-for-bert-in-your-browser-tensorflow-js.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgkDeGyxXiizIn1XZFIJvmCClozZ-_OtIOF2Re0emAmvrosaFIIVa1wbraBdxu-h3tbiUjdJyrfAgbbmSjESTWNuneM7HxE4noDo4wtbRFKknCiioOuVXQ4Pw9sP2mteSvwM7fQv9PQEgo/s1600/googledemo.gif
由 Philip Bayer,创意技术专家; Ping Yu,软件工程师; 和 Jason Mayes,开发者倡导者 撰写
现在有很多令人兴奋的研究正在探索 BERT 对语言的有用应用。我们想知道:如果我们在您的网络浏览器中让 BERT 更易于访问,会发生什么?这可能会带来哪些可能的用途?
向 Google 提出一个问题,例如“自由女神像有多高?”并从网络上获得答案(305 英尺)很容易。但是,没有简单的方法可以向特定内容(如新闻文章、研究论文或博客文章)提出自然语言问题。您可以尝试使用浏览器的“页面内查找”功能(CTRL + F),但这依赖于直接的词语匹配。如果您可以输入问题而不是要查找的词语,并让页面为您突出显示答案,那岂不是更容易吗?
为了探索这个想法,我们使用
MobileBERT 问答模型 原型制作了一个 Chrome 扩展程序,它允许我们向任何网页提出问题。使用 TensorFlow.js,该扩展程序根据页面的内容返回答案。该模型完全在浏览器会话中运行,因此不会将任何内容发送到服务器,从而保护隐私。
这是一个早期阶段的实验,我们在这里分享我们的发现,以说明如何从开源
TensorFlow.js BERT 模型 构建此类应用程序。探索我们得到我们想要的答案的示例和我们没有得到我们期望的准确答案的示例很有帮助。这让我们得以一窥其潜力和目前的局限性。我们希望看到这些示例将帮助每个人参与对话,并让每个人都能思考机器学习如何帮助语言的创意。
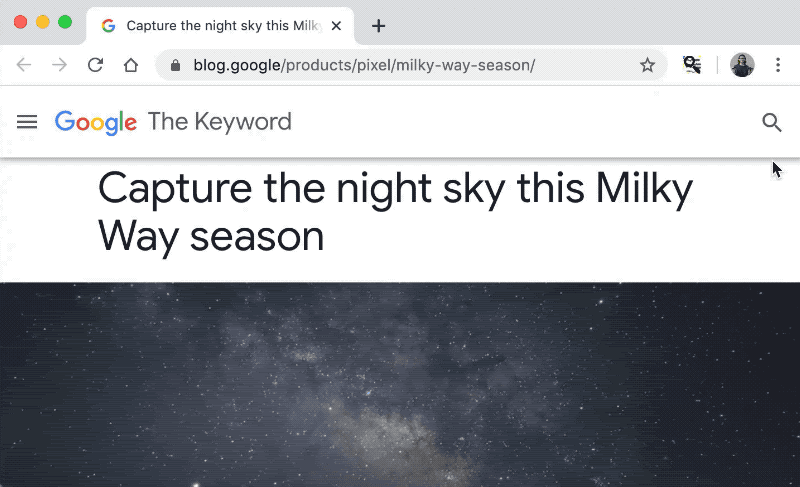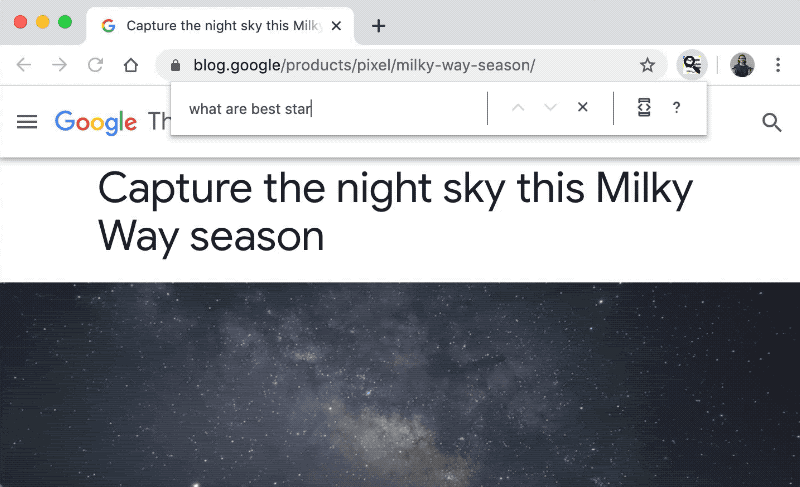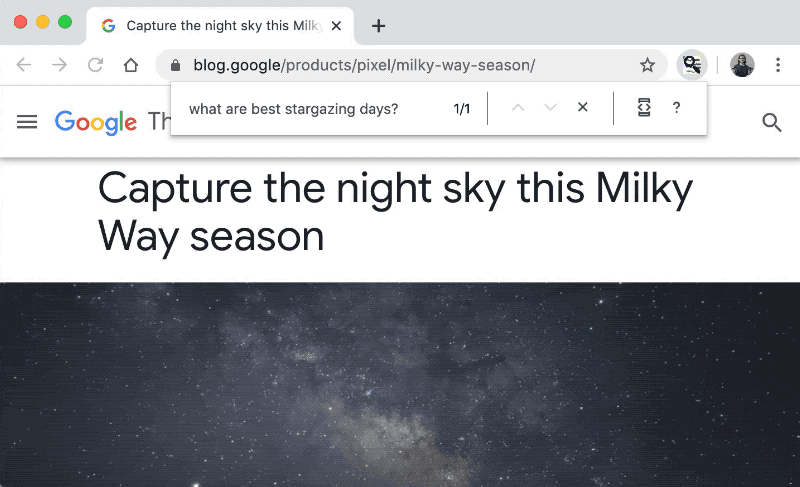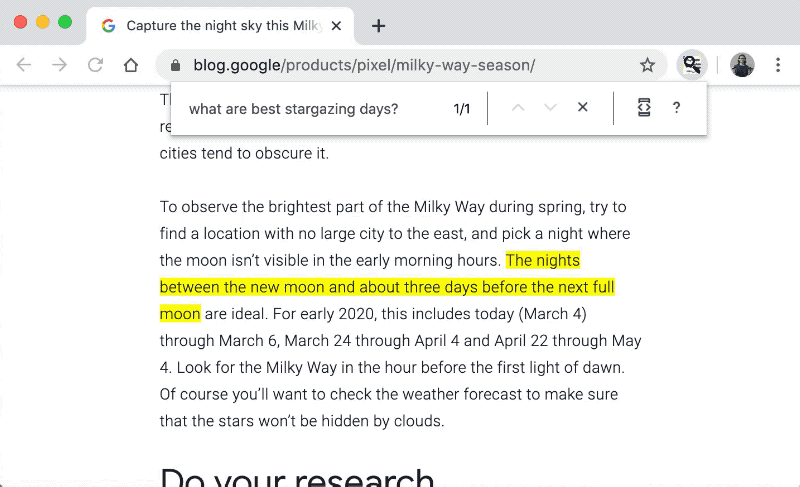 |
| 使用 Chrome 扩展程序,向有关该文章的问题询问并接收答案。 |
我们的发现
以下是一些我们找到的我们获得有用答案的结果
探索模型没有完全返回我们期望的答案的示例同样有趣。以下是我们找到的几个示例
- 这个产品页面 - 询问“搅拌器是由什么制成的?” 返回“冰模式以交错的间隔脉冲,以在几秒钟内均匀粉碎一整壶冰”,而不是答案“不含 BPA 的聚碳酸酯搅拌器”
- 这篇文章 - 询问“鲨鱼是真的吗?” 返回文本“鲨鱼!鲨鱼”,但询问相关问题“鲨鱼是如何工作的?” 给出了更有用的答案:“机械鲨鱼经常出现故障”
机器学习模型如何工作?
MobileBERT 问答模型 可用于构建一个能够以自然语言回答用户问题的系统。它是使用预先训练的
BERT 模型 在
SQuAD 1.1(斯坦福问答数据集)上微调而成的。这是一种新的预训练语言表示方法,它在各种自然语言处理 (NLP) 任务中获得了最先进的结果。我们很高兴地宣布,此模型
现在在 TensorFlow.js 中可用,供您自己使用。MobileBERT 模型是一种紧凑的 BERT 变体,可以部署到资源有限的设备上。
该模型将一段文字和一个问题作为输入,然后返回最有可能回答该问题的该段文字的一部分。所有操作都在网页浏览器中进行,因为我们使用的是
TensorFlow.js。这意味着隐私受到保护,您正在分析的网站上的任何文本都不会发送到任何服务器进行分类。
TensorFlow.js BERT API
使用该模型非常容易。请查看以下代码片段
<!-- Load TensorFlow.js. This is required to use the qna model. -->
<script src="https://cdn.jsdelivr.net.cn/npm/@tensorflow/tfjs"> </script>
<!-- Load the qna model. -->
<script src="https://cdn.jsdelivr.net.cn/npm/@tensorflow-models/qna"> </script>
<!-- Place your code in the script tag below. You can also use an external .js file -->
<script>
// Notice there is no 'import' statement. 'qna' and 'tf' is
// available on the index-page because of the script tag above.
// Load the model.
qna.load().then(model => {
model.findAnswers(question, passage).then(answers => {
console.log('Answers: ', answers);
});
});
</script>
如您所见,前两行从我们托管的脚本加载 TensorFlow.js 库和问答 (问答) 模型,以便我们可以执行问答搜索。这只需要调用一次 - 模型将一直加载,直到它保留在内存中。然后,我们可以重复调用 findAnswers(),并将两个字符串传递给它。第一个是用户想要提出的问题,第二个是我们要在其内搜索的文本(例如页面上的文本)。然后,我们将获得以下结构的
结果 对象
[
{
text: string,
score: number,
startIndex: number,
endIndex: number
}
]
您将获得一个对象数组,表示最能回答该问题的段落部分,以及表示其正确性的置信度的分数。我们还获得了答案文本的索引,以便轻松地找到答案文本在上下文字符串中的位置。就这么简单!有了这些数据,您现在可以突出显示找到的文本,返回更丰富的结果,或者实现您可能选择实现的任何创造性的想法。
如果您想自己尝试 MobileBERT 问答模型,我们很高兴地分享它现在是开源的,可以在我们的 Github 存储库
这里找到。如果您制作出令您自豪的东西,请在社交平台上使用
#MadeWithTFJS 与 TensorFlow.js 团队分享 - 我们非常乐意看到您创作的内容。






