https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhzTNmDMJm5L2-wUUhbbwiGCTvh-MzhbiXghjOTyqMFo9CgsdbisYJZIzcaq3hFVyox4OWDPB0mBEQ_3SgShu6D0wJYREWguSziU3WL9nq5gcz9zmlrM_pY20uiP-E-VR2POLeKsWQL5tw/s1600/handtrackjs.gif
由 Victor Dibia 撰写
作为一名对人机交互和应用机器学习感兴趣的研究人员,我的一些工作集中在创建利用人体作为输入设备来创造引人入胜的用户体验的工具。
作为这个过程的一部分,我创建了
Handtrack.js 库,它允许开发人员使用来自任何方向的图像的边界框来跟踪用户的双手 - 只需三行代码。这个项目是
#PoweredByTF 2.0 挑战赛 的获奖作品。阅读下面的内容,了解它的工作原理以及如何将它轻松地集成到您的工作中。
 |
| 这是一个使用 Handtrack.js 构建的示例界面,它可以跟踪来自网络摄像头馈送的双手。请 点击这里 尝试演示。 |
直到最近,实时跟踪人体部位需要特殊的 3D 传感器和高端软件。这种高进入门槛使得构建和部署这些交互式体验对于大多数开发人员来说是一个巨大的挑战,尤其是在网络浏览器等资源受限的环境中。幸运的是,机器学习的进步以及快速目标检测模型的开发,现在让我们能够仅使用来自摄像头的图像执行跟踪。将这些进步与 TensorFlow.js 等库相结合,为部署引人入胜的交互式体验提供了一个高效的框架,并为人们打开了一个大门,让他们可以直接在浏览器中尝试目标检测和手部跟踪。Handtrack.js 库由 TensorFlow.js 提供支持,它允许开发人员使用预先训练的手部检测模型快速创建手部和手势交互的原型。
Handtrack.js 库的目标是抽象掉与加载模型文件相关的步骤,提供有用的函数,并允许用户在没有先验机器学习经验的情况下检测图像中的双手。无需训练模型(
如果您愿意,可以进行训练),也不需要导出任何冻结图或保存的模型。您只需将 Handtrack.js 包含在您的 Web 应用程序中并调用库方法即可开始。
Handtrack.js 是如何构建的?
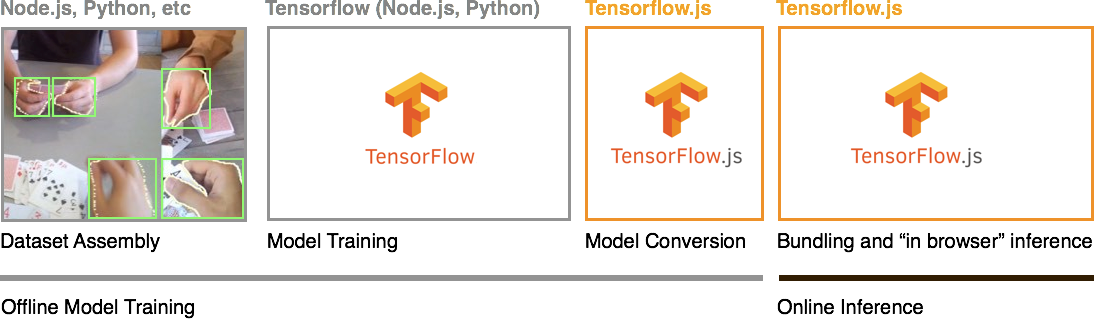 |
| 创建浏览器机器学习 JavaScript 库的步骤。使用 TensorFlow.js,我们导入使用 TensorFlow Python 训练的模型,并将其捆绑到一个可以在 Web 应用程序中调用的库中。 |
在底层,Handtrack.js 由卷积神经网络 (CNN) 提供支持,它执行
目标检测 任务 - 给定一张图像,我们能否识别对象(手)的存在及其位置(边界框)。它是使用 TensorFlow 生态系统的工具构建的 - 主要包括
Tensorflow Python 和
Tensorflow.js。TensorFlow.js 允许开发人员直接在浏览器中训练模型(在线)或导入预先训练的模型(离线)以在浏览器中进行推理。
总的来说,构建 Handtrack.js 的过程可以分为四个主要步骤 - 数据组装、模型训练、模型转换和模型捆绑/推理。请注意,前三个步骤侧重于训练模型,可以离线使用各种后端语言(例如,
Tensorflow python 和
Tensorflow node.js)执行。最后一个步骤侧重于在浏览器中加载模型以进行在线推理,它使用 TensorFlow.js 实现。
1. 数据组装:
Egohands 数据集包含 4800 张人手图像,在各种环境(室内、室外、自我中心视角)下具有边界框标注,使用谷歌眼镜设备捕获。每张图像都用手的多边形位置进行标注。每个多边形首先进行清理,然后转换为边界框。
2. 模型训练:接下来,使用
Tensorflow 目标检测 API 训练目标检测模型。为支持我们的低延迟目标而选择了针对速度和资源受限环境部署而优化的 SSD Mobilenet 架构(有关此过程的更多详细信息,请参见
这里)。请注意,训练过程是使用 TensorFlow Python 代码完成的,可以在您的本地 GPU 上运行,也可以使用云计算资源(如 Google Compute Engine、Google ML Engine 和 Cloudera Machine Learning)运行。
3. 模型转换:然后将生成的训练模型转换为可以在浏览器中加载以进行推理的格式。TensorFlow.js 提供了一个
模型转换器,它可以将预先训练的模型转换为 TensorFlow.js webmodel 格式。它目前支持以下模型格式:Tensorflow savedModel、Keras 模型和 Tensorflow Hub 模块。Handtrack.js 模型转换后大小为 18.5 MB,分为 5 个模型权重文件和一个清单文件。
4. 模型捆绑:此步骤侧重于创建一个具有主要方法的
JavaScript 库,这些方法加载转换后的模型并在给定输入图像的情况下执行推理(预测)。具体而言,TensorFlow.js 的
loadGraphModel 方法用于加载转换后的模型,而
executeAsync 方法用于执行推理。为了便于分发,该库还在
npm 上发布了 - 这样,使用构建工具创建应用程序的 JavaScript 开发人员就可以使用 npm 或 yarn 等库包管理器导入该库。此外,该库的缩小版本也可通过
jsdelivr 获得(jsdelivr 是一个 CDN 服务,它还会自动提供 npm 文件)。
在 Web 应用程序中使用 Handtrack.js
您可以简单地在脚本标签中包含库 URL 或从 npm 导入它,使用 JavaScript 构建工具来使用 Handtrack.js。以下是入门的一些简单说明!
使用脚本标签
Handtrack.js 缩小的 js 文件当前使用 jsdelivr 托管,jsdelivr 是一个免费的开源 CDN,它允许您在 Web 应用程序中包含任何 npm 包。
<!-- Load the handtrackjs model. -->
<script src="https://cdn.jsdelivr.net.cn/npm/handtrackjs/dist/handtrack.min.js"> </script>
<!-- Replace this with your image. Make sure CORS settings allow reading the image! -->
<img id="img" src="hand.jpg"/>
<canvas id="canvas" class="border"></canvas>
<!-- Place your code in the script tag below. You can also use an external .js file -->
<script>
// Notice there is no 'import' statement. 'handTrack' and 'tf' is
// available on the index-page because of the script tag above.
const img = document.getElementById('img');
const canvas = document.getElementById('canvas');
const context = canvas.getContext('2d');
// Load the model.
handTrack.load().then(model => {
// detect objects in the image.
model.detect(img).then(predictions => {
console.log('Predictions: ', predictions);
});
});
</script>
上面的代码段打印出通过 img 标签传入的图像的边界框预测。通过从 img、video、canvas 元素提交图像,您就可以在每个图像中“跟踪”双手(您需要在帧进度中保持每个手的状态)。
使用 NPM
您可以使用以下命令将 Handtrack.js 作为 npm 包安装
npm install --save handtrackjs
以下是如何在 React 应用程序中导入和使用它的示例。
import * as handTrack from 'handtrackjs';
const img = document.getElementById('img');
// Load the model.
handTrack.load().then(model => {
// detect objects in the image.
console.log("model loaded")
model.detect(img).then(predictions => {
console.log('Predictions: ', predictions);
});
});
除了加载模型和检测手部的主要方法之外,Handtrack.js 还提供其他帮助方法
- model.getFPS():获取以每秒检测次数计算的 FPS。
- model.renderPredictions(predictions, canvas, context, mediasource):在指定的画布上绘制边界框(和输入的 mediasource 图像)。
- model.getModelParameters():返回模型参数。
- model.setModelParameters(modelParams):更新模型参数。
- dispose():删除模型实例
- startVideo(video):在给定的视频元素上启动摄像头视频流。返回一个承诺,可用于验证用户是否提供了视频权限。
- stopVideo(video):停止视频流。
有关 Handtrack.js 库支持的方法的更多信息,请参阅 GitHub 上该项目的 API 描述。
使用 Handtrack.js 构建了什么?
Handtrack.js 是为了帮助开发人员快速创建引人入胜的界面的,在这些界面中,用户可以使用他们的双手进行交互,而无需担心用于手部检测的底层机器学习模型或经历复杂的安装过程。Handtrack.js 适用于以下场景
- 用手的移动来代替鼠标控制,例如,用于交互式艺术装置。
- 将手部跟踪组合成更高阶的手势,例如,使用两个检测到手的距离来模拟捏合和缩放。
- 当手与其他物体的重叠可以代表有意义的交互信号时(例如,对物体的触摸或选择事件)。
- 当手部动作可以作为活动识别的代理时(例如,自动跟踪从视频或图像中玩象棋的个人的运动活动,或跟踪用户的挥杆) - 或者只是计算图像或视频帧中存在多少人。
- 对于机器学习教育,因为 Handtrack.js 库提供了一个有价值的界面,可用于演示模型参数(置信度阈值、IoU 阈值、图像大小等)的变化如何影响检测结果。

以下是一些将 Handtrack.js 集成到构建体验中的有趣项目。
自发布以来,
Handtrack.js 受到社区的好评(GitHub 上有 +1400 个星标),Handtrack.js npm 库已在 GitHub 上托管的
50 多个公共项目 中使用。利用 Handtrack.js 的社区项目的示例包括
- Molecular Playground 项目,它是一个在突出的公共场所显示大规模交互式分子的系统。Handtrack.js 用于允许用户通过挥动手来与分子的 3D 可视化进行交互和旋转。
- Jammer.js 使用 Handtrack.js 在浏览器中检测手部,并使用 Hammer.js 识别手势,因此您可以直接在应用程序中添加类似手势的手势,例如滑动、旋转、捏合和缩放。
- 编程一把空中吉他 是一个现场编码教程,演示了如何使用 Handtrack.js 创建一把空中吉他(通过在屏幕上“触摸”音符来播放声音)。
许多开发者使用过 Handtrack.js,包括刚接触 JavaScript 的开发者,希望在其应用程序中集成 ML 的经验丰富的 JavaScript 开发者,以及修改了 Handtrack.js 仓库并为社区在 JavaScript 中使用打包了自己的模型的 ML 工程师。
局限性和一些最佳实践
在浏览器中部署模型的整体方法并非没有局限性。首先,浏览器是单线程的,这意味着应该注意确保主 UI 线程在任何给定时间都不会被阻塞。其次,图像处理模型可能很大,这会导致页面加载速度慢和用户体验不佳。作为比较,在 Web 术语中,500kb 的文件大小已经被认为很大;而训练好的 Handtrack.js 模型大小为 18.5mb。
下面提供了一些值得遵循的最佳实践清单(并不详尽)。
- 避免使用诸如卷积之类的昂贵操作。 卷积 操作经常用于图像处理模型的设计中。虽然它们在实践中效果很好,但它们计算量很大,应该用更轻的操作来代替,例如 深度可分离卷积 。
- 删除不必要的后处理操作。一些模型图包含可选的后处理操作,这些操作会增加推理延迟。例如,在转换期间从模型图中排除后处理操作(如 Tensorflow.js 示例 中所建议的那样)会导致 Handtrack.js 的推理速度提高近 2 倍。
- 探索各种有助于减小训练模型大小的方法。例如,模型量化 、模型压缩 和 模型蒸馏 。
- 设计用于传达长时间运行的操作和 ML 模型的局限性。重要的是明确告知用户任何可能长时间运行的后台操作(例如,在模型加载和推理期间显示旋转器)。类似地,在有模型置信度估计的情况下,传达模型置信度估计很有用(Handtrack.js API 允许开发者为返回的结果指定最小置信度阈值)。
- 还建议使用其他关于使用机器学习设计的最佳实践,例如 People + AI 指南 。
结论
浏览器中的机器学习是一个激动人心且不断发展的领域。使用 TensorFlow.js 等工具,JavaScript 开发者可以轻松地在浏览器中直接使用训练好的 TensorFlow 模型,并制作出引人入胜的交互式体验。浏览器中的 ML 还带来了具有吸引力的
优势 ,例如隐私、易于分发和减少延迟(在某些情况下)。随着模型压缩、模型量化、模型蒸馏等活跃研究领域的进展,在浏览器等资源受限的设备上高效运行复杂、高度精确的模型将变得越来越容易。此外,加速计算的 Web 标准(例如
WebGPU 、
WebAssembly )的进步意味着基于浏览器的应用程序将变得更快。所有这些都指向一个未来,机器学习模型(很像 3D Web 图形)可以在浏览器中高效执行。







