https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEimvGja9AcRoxBTtEqcAVVHoWTRI3gLnTY2uj4NfORlVnKbtsUxdnZje5SXi_ij7IP1pLG3JIngmKdq8WNsV9-rq9-0LtzpTinX4E96h60W3e624vg_n6E_k_hhC3QDTpTuuobWwnCcVJU/s1600/banner.jpeg
来自 Mercado Libre 应用机器学习团队的 Rodolfo Bonnin 的客座文章

简介
Mercado Libre 是拉丁美洲领先的市场平台,每天有数百万用户销售和购买数千万种不同的商品。从运输角度来看,商品最重要的信息之一是尺寸和重量,因为它们用于预测成本并预测配送中心的占用率。作为一个用户驱动的市场,此信息并不总是可用,我们发现可以通过提前预测来优化我们的流程。
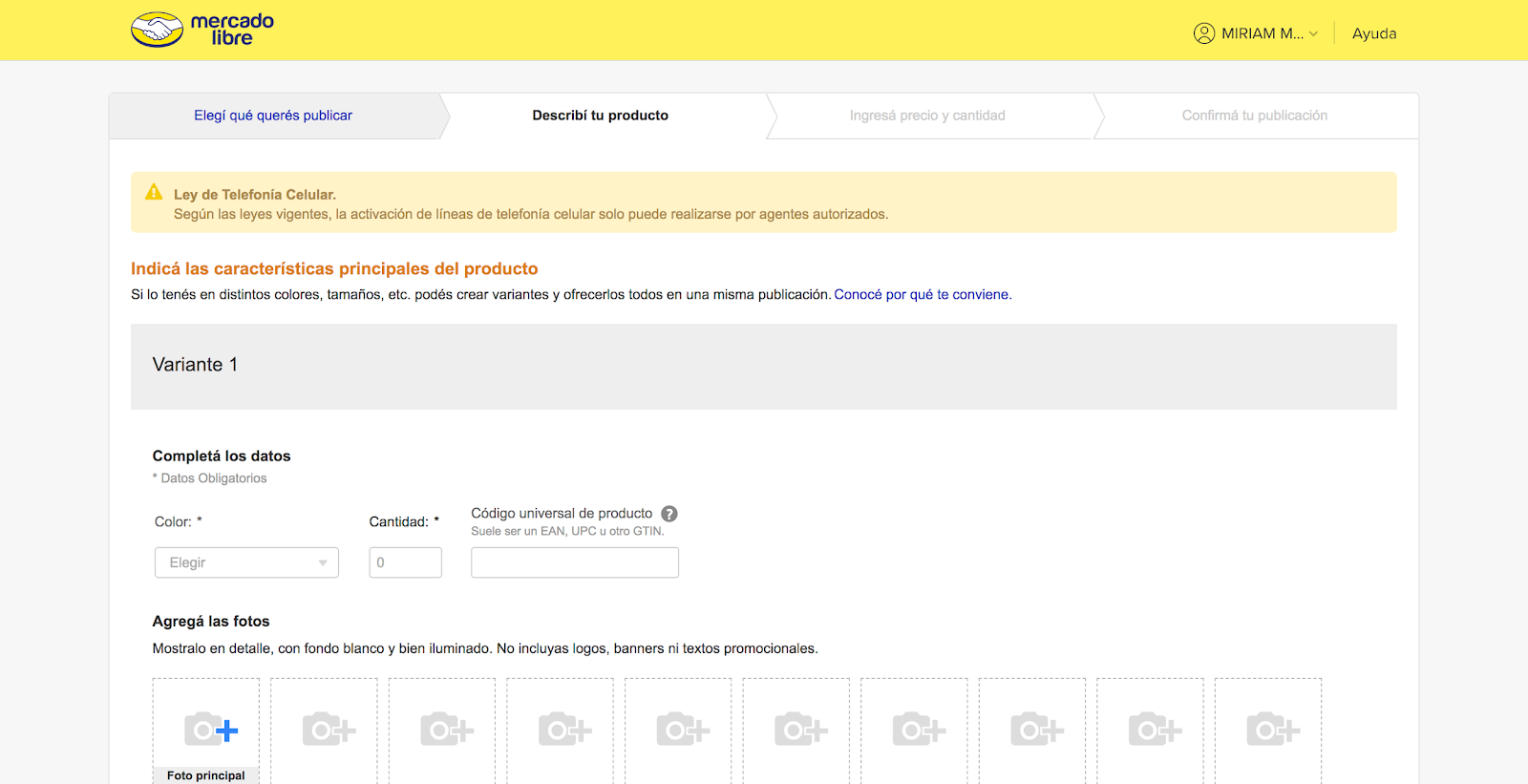 |
| 我们最初的商品提交屏幕没有要求测量或重量 |
Mercado Libre 是一个通用市场,因此商品可以是新手机(重量在 7-14 盎司之间,尺寸约为 5 英寸 x 5 英寸 x 2 英寸),也可以是重量为 175 磅、尺寸为 24 英寸 x 24 英寸 x 35 英寸的二手洗碗机。
最初,我们实施了一种查找机制,它包括根据我们配送中心、跨接点和验证第三方承运商之前商品的测量值来确定测量值和重量,并在异常值过滤过程之后。当然,此过程的覆盖率很低(已经测量的商品百分比很低)。
作为第二项措施,我们构建了基于单个商品特征(如类别和品牌/型号)的统计汇总的简单模型,并使用商品相似性指标将新商品映射到现有商品。这些方法的整体准确性较差,并且在许多情况下无法进行预测,因为没有足够的样本。
需要一个回归模型,能够从商品标题、描述、类别和一些其他属性等信息推断出测量值。重要的是,这些属性包括结构化和非结构化数据,这些数据很难用传统统计方法建模。该模型每分钟预测并保存 3k 个预测(每天 4M 个),并且 API 每分钟(每天 288M 个)为 200k 个请求提供服务(主要是预先保存的)。
数据和特征
在准备下一阶段时,在回顾商品发布流程后,我们确信,至少商品标题、商品描述(自由文本)以及类别和商品品牌可能是模型的关键特征。当然,必须清理和准备数据,才能为我们的项目所用。该项目的 ETL 部分的软件堆栈基于 scipy、pandas、numpy 和 scikit-learn。在确定特征后,就该对数据进行向量化了。
 |
| 模型特征联合的组成 |
为了对两个主要的基于文本的特征进行编码,我们对所有单词进行了分词和转为小写。接下来,我们需要找到一个合适的向量表示。对于该项目的第一次迭代,我们决定尝试使用关键字和 TF-idf 的方法,而不是我们将来要探索的 LSTM。TF-idf 是一种应用于文本数据的向量化技术,它将分词后的文档转换为矩阵。
模型
我们使用的模型是多层感知器,在 keras 中实现,使用 Tensorflow 后端。超参数和架构细节是通过对学习率、丢弃率、层数、核数和核维度进行网格搜索选择的(我们现在知道随机搜索是一种更好的方法)。
关于损失函数,我们尝试了多个实验,以查看哪一个更合适
mean_squared_error 提供了一个度量,即使它对误差进行了严重惩罚,但也过度拟合了异常值。
mean_absolute_percentage_error 特别保留了较小商品区域的异常值(较低的 1 千克覆盖了 50% 的商品)。
mean_absolute_error 对所有商品类别的整体和广泛优化很有用。
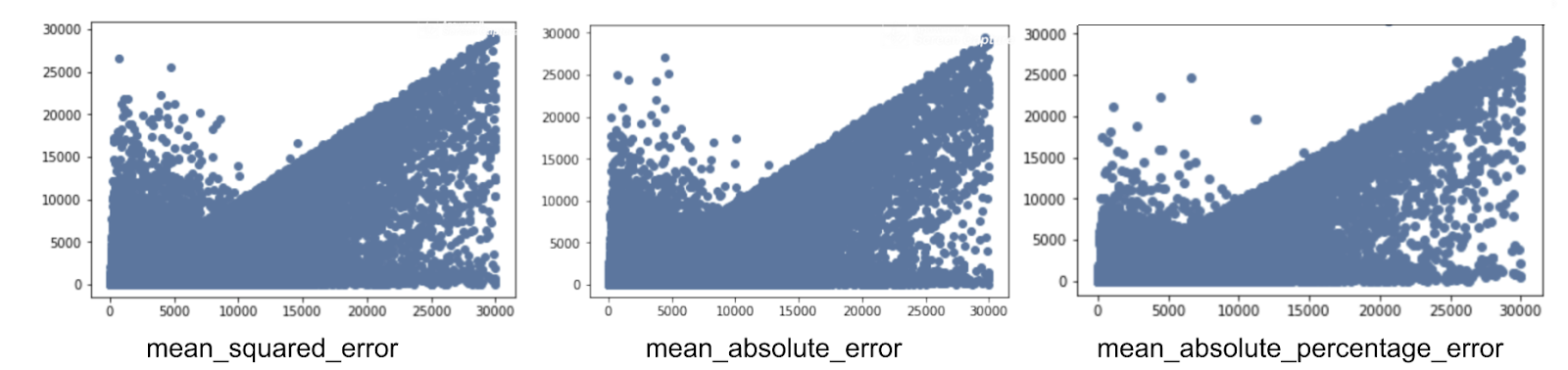 |
| 不同类型的损失函数的重量误差分布 |
 |
| 神经网络模型的总体架构 |
提供预测
该模型目前正在商品提交页面和配送中心包装计算器中使用,以预测货架的占用率以及在最终商品包装阶段使用的正确信封。
该 API 目前每分钟提供 3k 个预测或每天 4M 个预测。我们模型的推理时间为 30 毫秒,我们在 64GB RAM + 6 核心实例上提供服务,该实例有 13 个约 900MB 的 worker。
以下是一个示例 Json 响应
{
“dimensions”: {
“height”: 9,
“length”: 30,
“weight”: 555,
“width”: 24
},
“source”: {
“identifier”: “MLM633066627”,
“origin”: “high_coverage”
}
}
展望未来,我们计划进行额外的实验以优化模型质量,并根据配送中心的反馈来完善结果。使用 TensorFlow 使我们能够快速设计、迭代和将模型部署到生产环境中。
致谢
- 整个 Pymes 团队,尤其是 Mirko Panozzo、Conrado García Berrotarán、Kevin Clemoveki、Diego Piloni、Martín Ciruzzi 和 Esteban Tundidor。
- Francisco Ingham 帮助处理语法、风格和内容。
- Joaquin Verdinelli 协调与 Google 的编辑和沟通工作。
- Constanza Stahl 帮助处理图形。
- Cynthia Bustamante 提供了总体协调帮助






