https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjjO_uY0MV_-7U6hcWwGi37Z1Oek0PmMe9jtoPtCuUAnH0-6FrCTNbnKfcD4oNDv0WRr4V7mTX0v7T1vhmA6dmyuoEiEKPCBMQXrdCtBDROAJdPMEYGshvUu641W05CRzrLQg6WE2uUzDs/s1600/map.png
Abraham Poorazizi、Mahmood Khordoo 和 Mahsa Amini 的客座文章
 灾难监测
灾难监测 是
#PoweredByTF 2.0 挑战赛 的获奖作品,是一个危机映射平台,它从推特收集数据,从推文中提取与灾难相关的資訊,并在地图上可视化结果。它使用户能够快速地一目了然地找到不同地理区域的信息,并确定灾难造成的物理限制,例如无法通行的桥梁或道路,并采取明智的行动。这些信息有助于政府官员和灾难响应者(例如人道主义组织、救灾机构或当地行动者)回答以下问题
- 灾难发生的时间?
- 受灾地区在哪里?
- 灾难的影响是什么?
这些问题的答案提供了有关事件的空间(哪里)、时间(何时)和主题(什么)信息。从实时信息分析中获得的见解对于从准备到应对和恢复的灾难每个阶段的决策者来说都是宝贵的。
挑战
越来越多的社交媒体在灾难期间发挥着关键作用,传播信息。受灾公民和受灾地区以外的人员以及新闻媒体都在使用社交媒体在野火、地震、洪水和龙卷风期间收集和分享与灾难相关的信息。例如,在 2013 年加拿大阿尔伯塔省卡尔加里洪水期间,人们大量使用社交媒体发布有关正在发生的事件的信息、照片和突发新闻。除了公民外,卡尔加里的官方应急响应者,如卡尔加里警察局和卡尔加里市,也使用社交媒体广播安全关键信息和情况更新。这标志着公民和应急响应组织都将转向利用社交媒体的力量,在紧急情况下实时传播信息和意识。
然而,在将社交媒体视为灾难应对信息来源时,也存在一些挑战。特别是,社交媒体流包含大量无关的信息,例如谣言、广告甚至错误信息。因此,使用社交媒体数据(如推文)的一个主要挑战是如何处理这些数据并将可靠且相关的信息传递给灾难响应者和公民。另一个挑战源于社交媒体上流动的海量信息,以及如何在实时分析这些信息。最后,社交媒体信息简短(例如推文的 280 个字符)且非正式,这在应用用于处理新闻文章等结构化长篇文本的相同方法时带来了挑战。这些方法并不总是对非正式的书面内容有效,并可能导致结果不佳且误导。
灾难监测旨在解决这些问题——它旨在将推文转换为可靠的信息来源,从而使灾难应对和恢复中有效地使用社交媒体信息成为可能。它使用机器学习来识别与灾难相关的推文,提取地名,并在地图上绘制结果。下一部分介绍了技术架构,并描述了系统的工作原理。
解决方案
技术架构
灾难监测使用开源软件、开放标准和开放数据构建:TensorFlow 2.0、Node.js 和 Express、Vue.js、Vuetify 和 Mapbox GL JS 用于创建系统组件。它使用 Twitter 的流式 API 收集推文,使用 TensorFlow 2.0 构建的深度学习模型分析推文,并将与灾难相关的推文显示在地图上。该应用程序托管在亚马逊的 AWS 基础设施上。下图显示了灾难监测的整体架构。
 |
| 图 1. 灾难监测的整体架构 |
工作流程从数据收集过程开始。后端 API 使用基于关键词的抽样方法,使用 Twitter 的流式 API 收集推文。在这种情况下,使用
CrisisLex.org 开发的灾难相关词语参考词典作为关键词。CrisisLex 是一个包含 380 个与灾难相关的词语的词典,这些词语在 2012 年 10 月至 2013 年 7 月期间美国、加拿大和澳大利亚发生的各种灾难期间频繁出现在相关推文中。
然后,API 将推文发送到使用 TensorFlow 2.0 for Python 构建并作为
Flask 应用程序公开的深度学习模型。该模型分析推文的文本内容,以评估其与洪水、地震、飓风、龙卷风、爆炸和爆炸的关联性。然后将相关推文发送到地理解析器,地理解析器从文本中提取地名并对其进行地理编码。最后,结果将发送到前端进行可视化。
文本处理
内容分析的第一步是训练一个文本分类器,以在进行任何进一步分析之前去除无关的信息。本项目使用监督式深度学习方法来执行文本分类任务。分类器使用由
CrisisLex.org 提供的一组带注释的推文,称为“CrisisLexT6”。它包含来自六个不同灾难类别(包括洪水、地震、飓风、龙卷风、爆炸和爆炸)的 60,000 条推文,分为两大类:主题内和主题外。为了准备推文进行训练过程,执行了一组标准文本预处理操作。首先,删除所有非单词,包括 URL、用户提及、标点符号、空格和特殊字符。之后,为了避免出现太多变量,将大写字母更改为小写,并删除最常出现的地名。接下来,执行重采样以最小化类别不平衡。然后,在标记化过程中将每条推文拆分为标记。然后,对剩余的标记执行向量化过程,使用词嵌入创建一组特征向量。最后,使用 Keras 的 Sequential 模型 API 训练模型,使用特征向量。有关更多详细信息,请参见以下笔记本:
建模、
分析.
一旦无关的推文被过滤掉,并将主题内的推文分类为六个类别,这些推文将被发送到一个名为
CLAVIN 的地理解析工具。地理解析是指识别文本中隐含的空间信息(例如地名)并将它们与地理坐标关联起来的过程。最后,结果(包括推文 ID、文本、类别、模型的准确性、地名和地理坐标)将发送到客户端进行

结论
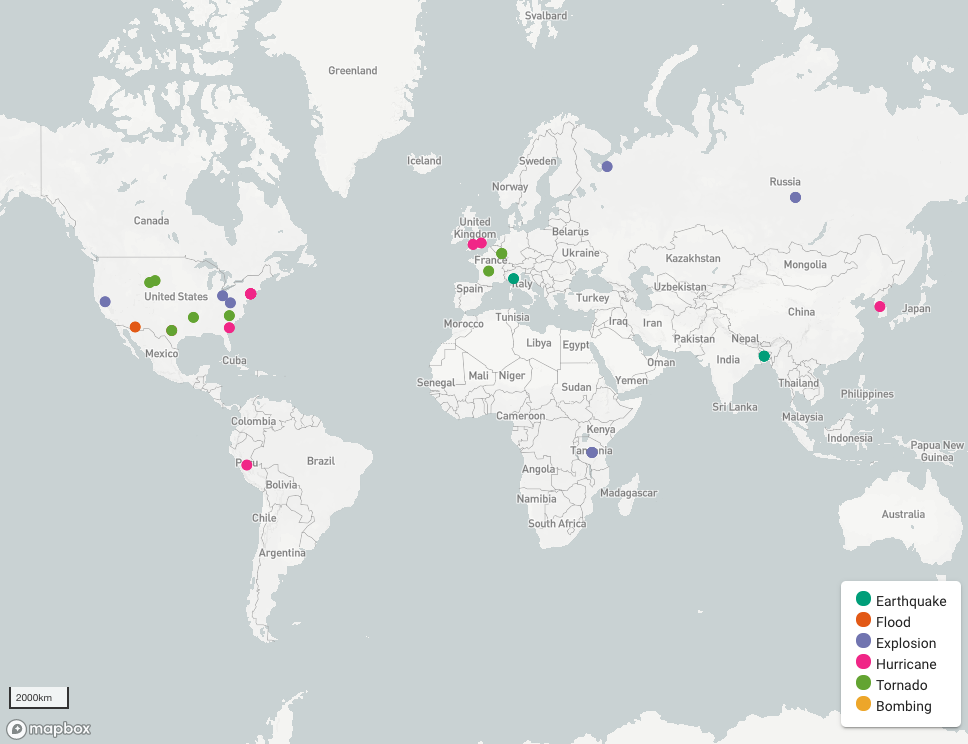
我们监控了灾难监测在从美国中西部最近的龙卷风到日本地震的几个现实世界灾难中的表现。结果表明,灾难监测能够检测到与危机相关的推文,这些推文提供有关事件发生地点和正在发生的事件影响的及时信息。这突出了社交媒体信息可以提供的主题(语义)、时间和地理空间信息价值。它还表明了社交媒体信息作为补充信息来源的潜力,可以帮助公民、决策者和灾难响应者回答“哪里”、“何时”和“什么”问题。
在当前的实现中,灾难监测仅使用 Twitter 作为信息来源。虽然结果很有希望,但整合其他信息来源(例如官方新闻媒体和其他社交媒体平台)将有助于改进数据验证过程,从而获得更现实的结果。此外,当前的原型只使用文本内容来检测灾难事件,而忽略了视觉内容(照片/视频)。社交媒体信息中的视觉内容分析可以提供背景信息,并有助于态势感知,正如俗语所说,“一张图片胜过千言万语”。在这种情况下,一个有趣的方向是将图像识别服务集成到灾难监测中。
我们鼓励您使用在线应用程序
此处 进行尝试,并探索我们的 GitHub 代码库以深入了解代码库





