https://blog.tensorflowcn.cn/2019/04/the-power-of-building-on-accelerating-platform-deep-variant.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhwvgsFzKuEwY4Icf7PRxrtzF3XQVdI8HPrRWffKe7BvbM7DIaYe0qZOrssAc52jTePss8_sWGRY9zX8NPX3V_do8_oOBPAE0adzlbEHmrB8jqbF-d-wC80NAHMG3otnwU9Lg8FFgtnIXM/s1600/fig1.png
发布者 Andrew Carroll,Lizzie Dorfman
编者注:本文与
Google DeepVariant 博客 上的相同内容同时发布。
Google Brain 的
基因组学团队 开发了
DeepVariant,这是一种用于分析个人 DNA 序列的开源工具。DeepVariant 建立在
TensorFlow 之上。
DeepVariant 的先前版本(v0.7)在端到端速度方面取得了三倍的改进,与之前的版本(v0.6)相比,成本相应降低。这种速度改进的主要原因是 DeepVariant 能够利用新的
英特尔® 高级矢量扩展 (AVX-512) 指令集。AVX-512 的使用说明了系统和平台的最新进展如何加速和影响应用研究。
什么是 AVX-512 指令集和 TF-MKL?
英特尔 CPU 为许多个人和大型系统提供计算执行能力,并在
Google Cloud Platform 中得到广泛使用。处理单元有一个寄存器,他们可以使用数据填充该寄存器。处理单元一次只能对寄存器内容应用一种类型的操作。因此,大量的优化用于组织需要相同操作的项目,并将它们同时加载到寄存器中。
您可以将此想象成一个活跃的交通枢纽,公共汽车不断地前往不同的目的地。枢纽必须决定发送哪些公共汽车,以最大限度地提高每辆公共汽车上的人数,而不会让任何人等待太长时间才能搭乘。
寄存器的大小以及有意义地填充它的能力限制了处理速度。AVX-512 指令集是一种专门设计的方法,用于打包此寄存器,以允许处理器一次对更多信息进行操作。在这个比喻中,它对应于为常见目的地提供更大的公共汽车。有关更多详细信息,请参见
英特尔文档。
在 TensorFlow 中训练和应用深度学习模型的过程涉及大量相同类型的向量/矩阵操作。英特尔开发的
英特尔数学内核库 (MKL) 用于深度神经网络 允许 TensorFlow 应用程序有效地填充这些更大的寄存器,从而使英特尔 CPU 能够为这些应用程序更快地进行计算。
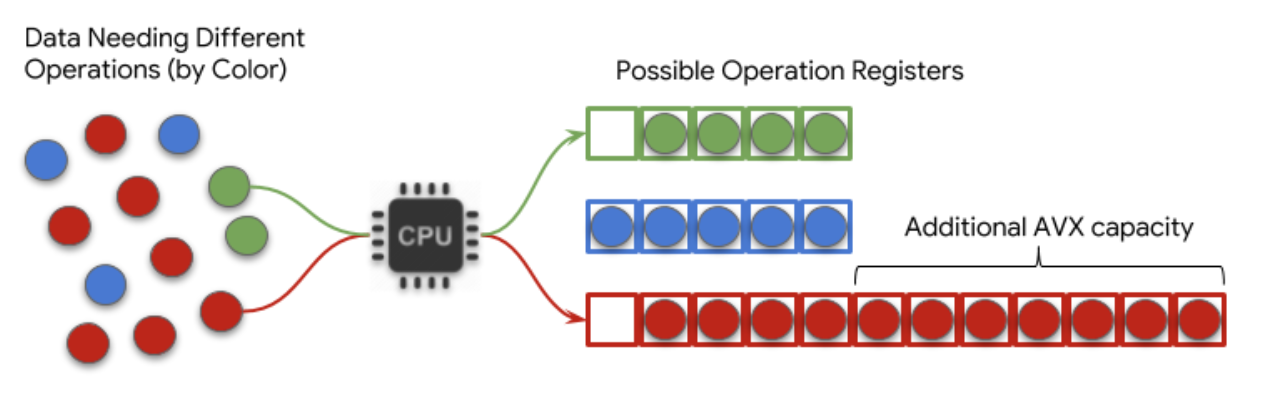 |
| 图 1. AVX-512 在 TF-MKL 中的优势的简化概念示意图 |
量化 TF-MKL 和英特尔 AVX-512 对 DeepVariant 的影响
DeepVariant 在测序数据中调用变异的过程中运行三个不同的步骤(有关更多详细信息,请参见
出版物 或
Google AI 博客文章)。计算量最大的步骤是 call_variants** **阶段,它使用卷积神经网络对个人基因组数据中与参考位置不同的位置进行分类。这些结果可以在临床上用于诊断和治疗患者,并在研究中用于发现和开发新药物。
在 DeepVariant 的先前版本(v0.6)中,call_variants 步骤需要在配备英特尔 Skylake CPU 的 64 核机器上运行 11 小时 11 分钟。对于 DeepVariant 的最新版本(v0.7),我们优化了 DeepVariant 对 TensorFlow 的使用,以充分利用新的 TF-MKL 库。通过利用这些创新,在相同 64 核机器上执行 call_variants 时,运行时间缩短至 3 小时 25 分钟。
由于 DeepVariant v0.6 已经使用了一些来自英特尔库的优化,因此我们决定,为了公平地量化 TF-MKL 的加速效果,我们应该使用不包含任何优化的 TensorFlow 库重建 DeepVariant(v0.7)的完全相同版本。在相同的 64 核机器上,call_variants 在这种配置下需要 14 小时 7 分钟。
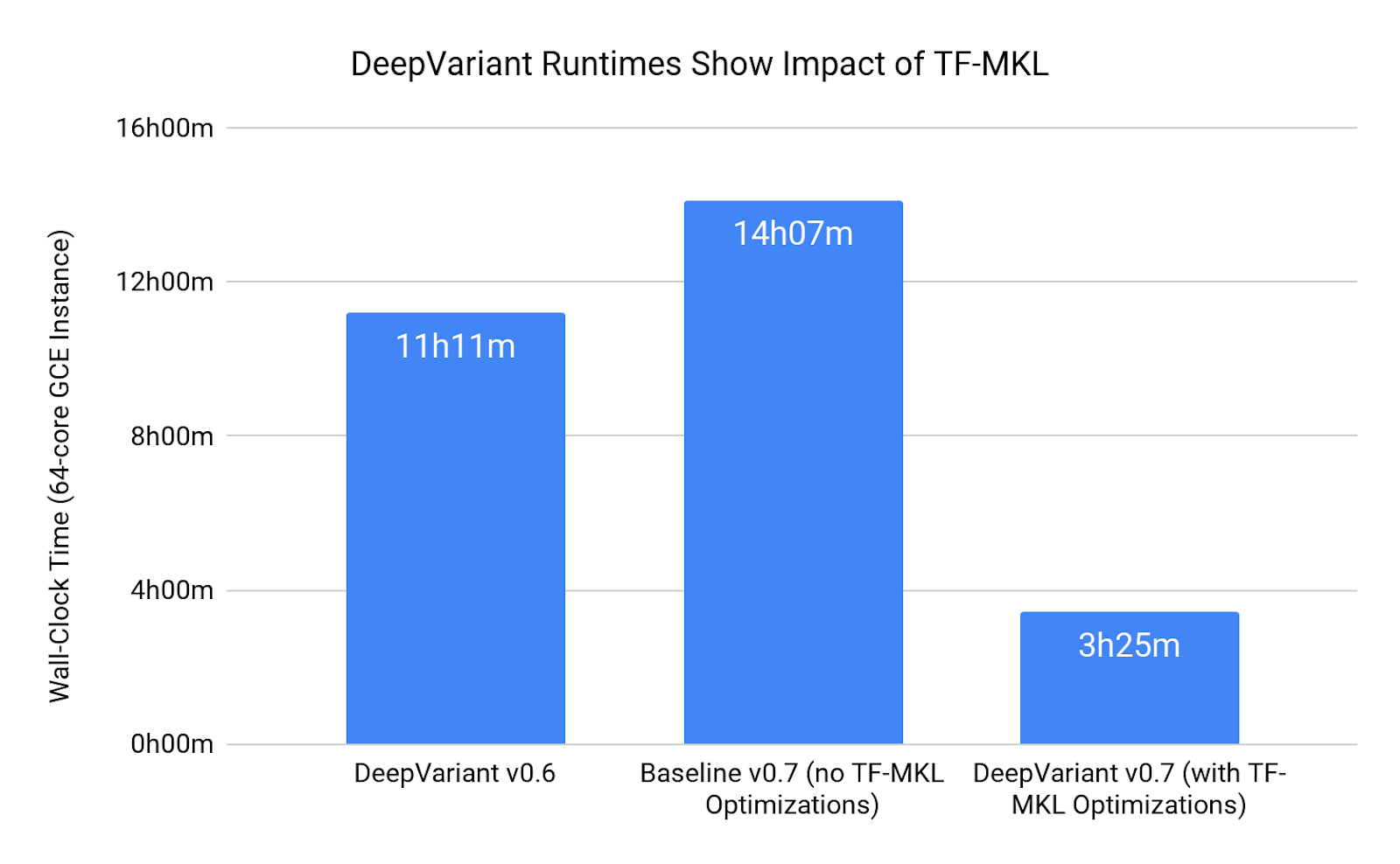 |
| 图 2. DeepVariant v0.7 通过使用 TF-MKL 实现的运行时间加速 |
DeepVariant Github 页面 提供了有关如何使用预安装了所有正确库的 Docker 容器的说明,因此您可以在本地或云环境中运行 DeepVariant 并利用这种速度改进。
这种速度改进,连同我们希望稍后详细介绍的其他优化,导致成本相应降低。在典型覆盖范围的全基因组基准测试中,DeepVariant 在 DeepVariant v0.7 中在 Google Cloud Platform 上运行的成本为 2-3 美元,与 DeepVariant v0.6 相比,成本降低了三倍。
基于快速改进平台的力量
此博客详细介绍了我们如何继续努力提高 DeepVariant 的速度(以及在
准确性 和
可扩展性 方面的改进)。通过使用自然地提供持续改进优势的技术,这项工作变得更加容易,因为这些技术得益于其开发人员和用户群体的持续努力。TensorFlow 的广泛采用确保了 Google 内部和外部的许多团队都在积极努力使其更快更好。英特尔为 AVX-512 加速 TensorFlow 的工作就是一个很好的例子。
此外,随着新一代英特尔 CPU 的推出,AVX-512 的性能得到了显着提升。新的英特尔 Skylake CPU 比英特尔 Broadwell CPU 更快地执行 DeepVariant。由于我们预计随着向量操作的并行化变得越来越重要,这种趋势将继续下去,我们还预计 DeepVariant 的速度将在下一代英特尔 CPU 中自然得到提升,甚至超过一般应用程序所看到的速度提升。
这就是基于快速改进平台(无论是硬件、软件还是介于两者之间的技术)的优势。这就是基因组学和信息学交叉点如此激动人心的原因。随着我们的
基因组测序能力 指数级增长,分析这些基因组的硬件和软件必须随之提升。






