https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgA97JpZpO2Euak4jUDxUzFmnUa_yCV09uT611Rj4MQ0plGNPQB0pixnWrsvu3qeF-rZCRwDHuW2QSHEojYmmr4DmS6AIAjTGbz00ECDJR_thboAOvoXvgpFlNNnGbP-XSNQG-jeucY5Xs/s1600/0_Bz70Bl42gW3PFnCV.gif
TensorFlow 团队发布
在移动设备上运行计算密集型机器学习模型的推理由于设备的处理能力和功率有限,因此资源需求很高。虽然转换为定点模型是加速的一种途径,但我们的用户要求我们提供 GPU 支持,作为一种选择,以在不增加额外复杂性和量化可能导致的精度损失的情况下加速原始浮点模型的推理。
我们倾听了您的需求,并很高兴地宣布,您现在可以使用移动 GPU 为选定的模型(如下列出)加速,这得益于 TensorFlow Lite GPU 后端的开发人员预览版发布;它将在不支持的部分模型中回退到 CPU 推理。在接下来的几个月里,我们将继续添加额外的操作并改进 GPU 后端功能。
此新后端利用
今天,我们发布了新 GPU 后端的预编译二进制预览版,让开发人员和机器学习研究人员可以尽早体验这项令人兴奋的新技术。计划在 2019 年晚些时候发布完整的开源版本,并结合我们从您的使用体验中收集到的反馈。
 |
| 使用 TensorFlow Lite CPU 浮点推理进行面部轮廓检测(不是人脸识别)。通过在未来利用新的 GPU 后端,推理速度可以从 Pixel 3 和三星 S9 上的约 4 倍提高到 iPhone7 上的约 6 倍。 |
GPU 与 CPU 性能
在 Google,我们已经将新的 GPU 后端用于我们的产品中几个月,它加速了计算密集型网络,这些网络为我们的用户提供了重要的用例。
对于 Pixel 3 上的人像模式,Tensorflow Lite GPU 推理将
前景-背景分割模型 的速度提高了
4 倍以上,以及
新的深度估计模型 的速度提高了
10 倍以上,与使用浮点精度进行 CPU 推理相比。在
YouTube 故事 和
游乐场贴纸 中,我们的
实时视频分割 模型的速度提高了 5-10 倍,涵盖各种手机。
我们发现,一般来说,对于各种各样的深度神经网络模型,新的 GPU 后端
比浮点 CPU 实现快 2-7 倍。下面,我们在 Android 和 Apple 设备集中对 4 个公开模型和 2 个内部模型进行了基准测试,这些模型涵盖了开发人员和研究人员在各种用例中遇到的常见用例。
公开模型
- MobileNet v1(224x224)图像分类 [下载]
(专为移动和嵌入式视觉应用而设计的图像分类模型)
- 用于姿势估计的 PoseNet [下载]
(估计图像或视频中人(们)姿势的视觉模型)
- DeepLab 分割(257x257) [下载]
(图像分割模型,为输入图像中的每个像素分配语义标签(例如,狗、猫、汽车))
- MobileNet SSD 对象检测 [下载]
(检测具有边界框的多个对象的图像分类模型)
Google 专有用例
- MLKit 使用的面部轮廓
- 实时视频分割,由 游乐场贴纸 和 YouTube 故事 使用
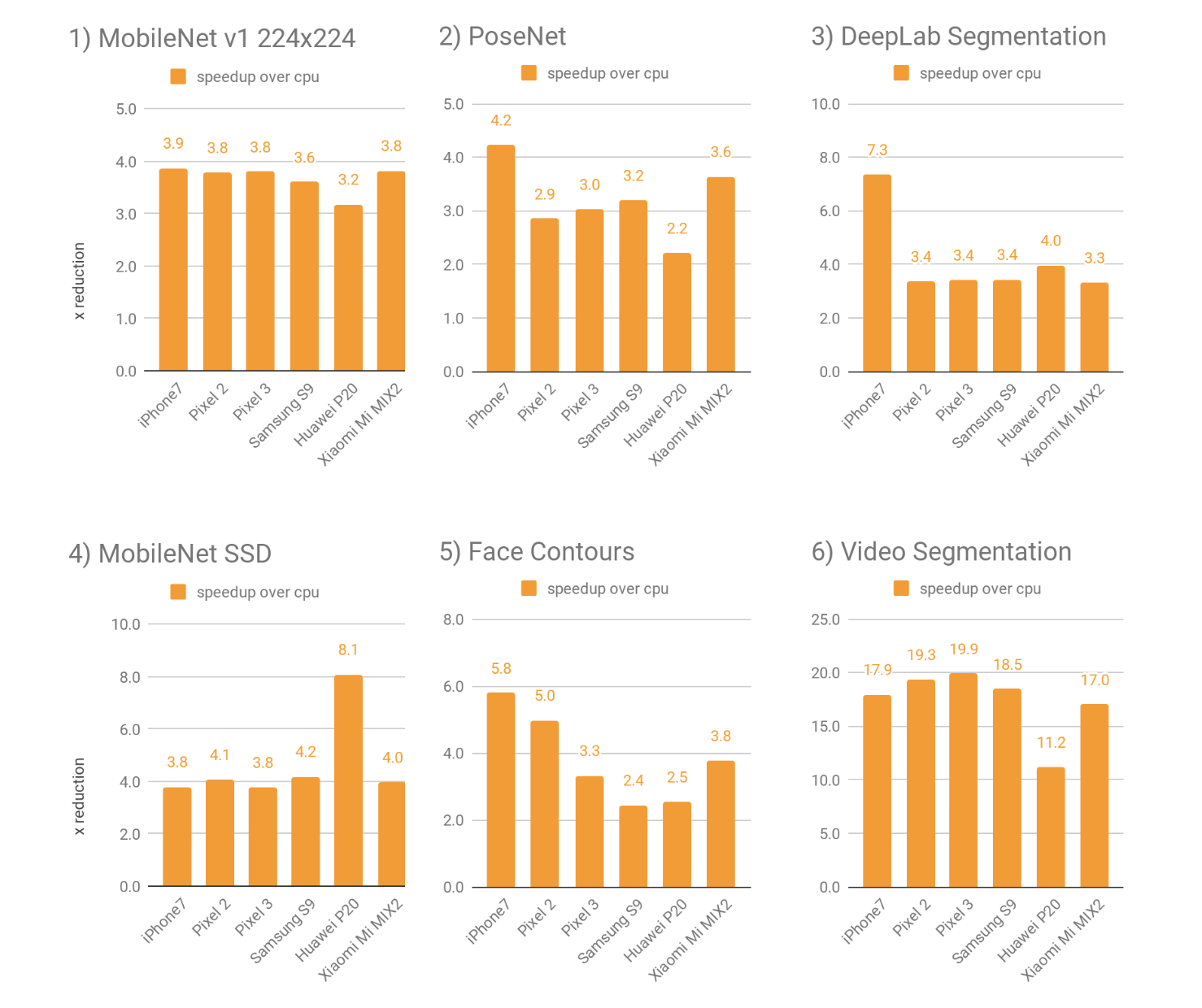 |
| 表 1. 在各种 Android 和 Apple 设备上的 6 个模型中,GPU 与基线 CPU 性能相比的平均性能加速。更高的乘数表示更好。 |
GPU 加速在更复杂的深度神经网络模型上最为显著,这些模型更适合 GPU 利用,例如密集预测/分割或分类任务。在非常小的模型上,加速效果可能较小,而使用 CPU 可能会带来避免内存传输固有延迟成本的好处。
如何使用它?
教程
最简单的入门方法是按照我们的 教程 使用 TensorFlow Lite 演示应用程序与 GPU 代理。下面也简要概述了使用方法。有关更多信息,请参阅我们的 完整文档。
有关分步教程,请观看 GPU 代理视频
使用 Java 为 Android 开发
我们已经准备了一个完整的 Android 存档 (AAR),其中包含具有 GPU 后端的 TensorFlow Lite。编辑您的 gradle 文件以包含此 AAR 而不是当前版本,并将此代码段添加到您的 Java 初始化代码中。
// Initialize interpreter with GPU delegate.
GpuDelegate delegate = new GpuDelegate();
Interpreter.Options options = (new Interpreter.Options()).addDelegate(delegate);
Interpreter interpreter = new Interpreter(model, options);
// Run inference.
while (true) {
writeToInputTensor(inputTensor);
interpreter.run(inputTensor, outputTensor);
readFromOutputTensor(outputTensor);
}
// Clean up.
delegate.close();
使用 C++ 为 iOS 开发
步骤 1. 下载 TensorFlow Lite 的二进制版本。
步骤 2. 修改您的代码,以便在创建模型后调用
ModifyGraphWithDelegate()。
// Initialize interpreter with GPU delegate.
std::unique_ptr interpreter;
InterpreterBuilder(model, op_resolver)(&interpreter);
auto* delegate = NewGpuDelegate(nullptr); // default config
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
while (true) {
WriteToInputTensor(interpreter->typed_input_tensor(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor(0));
}
// Clean up.
interpreter = nullptr;
DeleteGpuDelegate(delegate);
现在支持加速哪些操作?
GPU 后端目前支持选定的操作(请参阅
文档)。当您的模型仅包含这些操作时,运行速度最快;不支持 GPU 的操作将自动回退到 CPU。
它是如何工作的?
深度神经网络按顺序运行数百个操作,这使得它们非常适合 GPU,GPU 的设计初衷是处理面向吞吐量的并行工作负载。
当在 Objective-C++ 中调用
Interpreter::ModifyGraphWithDelegate() 或在 Java 中通过使用
Interpreter.Options 调用
Interpreter 的构造函数来间接调用时,GPU 代理将被初始化。在此初始化阶段,将根据从框架接收的执行计划构建输入神经网络的规范表示。使用这种新的表示,将应用一组转换规则。这些规则包括但不限于
- 剔除不需要的操作
- 用具有更好性能的等效操作替换操作
- 合并操作以减少生成的着色器程序的最终数量
根据此优化的图,生成并编译计算着色器;我们目前在 Android 上使用 OpenGL ES 3.1 计算着色器,在 iOS 上使用 Metal 计算着色器。在创建这些计算着色器时,我们还采用各种特定于体系结构的优化,例如
- 应用某些操作的专门化,而不是使用它们的(较慢的)通用实现
- 放松寄存器压力
- 选择最佳工作组大小
- 安全地调整精度
- 重新排序显式数学运算
在这些优化结束时,着色器程序将被编译,这可能需要几毫秒到半秒的时间,就像移动游戏一样。着色器程序编译完成后,新的 GPU 推理引擎就可以投入使用了。
在每次输入的推理过程中
- 必要时将输入移动到 GPU: 如果输入张量尚未存储为 GPU 内存,则框架会通过创建 GL 缓冲区/纹理或 MTLBuffers 来使 GPU 可以访问这些张量,同时还可以复制数据。由于 GPU 在 4 通道数据结构方面效率最高,因此通道大小不等于 4 的张量将被重新整形为更适合 GPU 的布局。
- 执行着色器程序: 上述着色器程序将被插入到命令缓冲区队列中,GPU 将执行这些程序。在此步骤中,我们还管理 GPU 内存以供中间张量使用,以尽可能地减少后端的内存占用。
- 必要时将输出移动到 CPU: 深度神经网络完成处理后,框架将结果从 GPU 内存复制到 CPU 内存,除非网络的输出可以直接渲染到屏幕上,并且不需要此传输。
为了获得最佳体验,我们建议优化输入/输出张量复制和/或网络体系结构。有关此类优化的详细信息,请参阅
TensorFlow Lite GPU 文档。有关性能最佳实践,请阅读本
指南。
它有多大?
GPU 代理将在 Android armeabi-v7a APK 中添加大约 270KB,在 iOS 中添加大约 212KB(每个包含的体系结构)。但是,后端是可选的,因此如果您没有使用 GPU 代理,则无需包含它。
未来工作
这只是我们 GPU 支持工作的第一步。除了社区反馈外,我们还打算添加以下改进
- 扩展操作覆盖范围
- 进一步优化性能
- 发展和完善 API
我们鼓励您在我们的
GitHub 和
StackOverflow 页面上留下您的想法和评论。
致谢
Andrei Kulik、Juhyun Lee、Nikolay Chirkov、Ekaterina Ignasheva、Raman Sarokin、Yury Pisarchyk、Matthias Grundmann、Andrew Selle、Yu-Cheng Ling、Jared Duke、Lawrence Chan、Tim Davis、Pete Warden、Sarah Sirajuddin






