 与测量值相比,模型预测相当准确。初始数据集的均方误差 (MSE) 发现为:MSE(i)=3.93 10^-7。该模型对对应于更新数据集的时间段内的裂纹尺寸的预测如下所示。
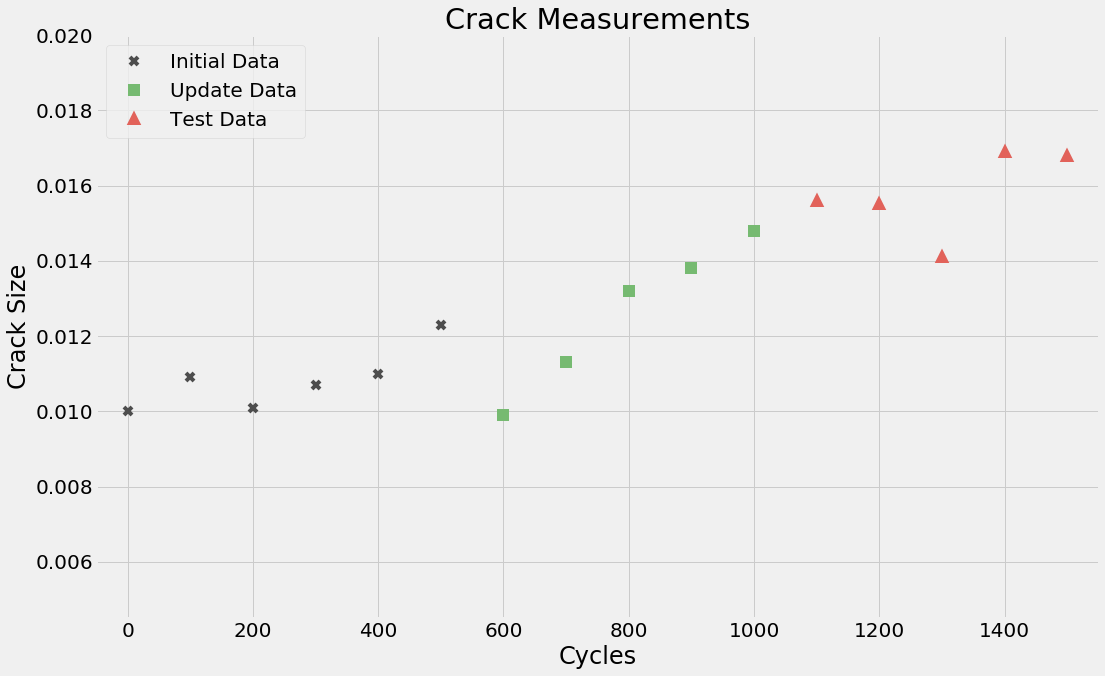
与测量值相比,模型预测相当准确。初始数据集的均方误差 (MSE) 发现为:MSE(i)=3.93 10^-7。该模型对对应于更新数据集的时间段内的裂纹尺寸的预测如下所示。  很明显,初始模型的预测不再准确。更新数据点的 MSE 变为 MSE(u)=5.67 10^-6,几乎是初始误差 MSE(i) 的 14 倍!此外,随着循环次数的增加,模型预测和观察到的裂纹尺寸在更新数据集中存在明显的差异。因此,需要改进模型以提高其准确性。
很明显,初始模型的预测不再准确。更新数据点的 MSE 变为 MSE(u)=5.67 10^-6,几乎是初始误差 MSE(i) 的 14 倍!此外,随着循环次数的增加,模型预测和观察到的裂纹尺寸在更新数据集中存在明显的差异。因此,需要改进模型以提高其准确性。
## Inputs: State Vector - x_prev, Covariance Matrix - cov_prev, # States - num_st, UKF Parameter - kappa
## Output: Sigma Points Matrix - sig
[eigval, eigvec] = tf.linalg.eigh(cov_prev) # Eigen Decomposition of the covariance matrix
S_tf = tf.diag(tf.sqrt(eigval))
sqrt_cov = tf.matmul(tf.matmul(eigvec, S_tf), tf.matrix_inverse(eigvec)) # Square-root of the covariance matrix
eta = tf.sqrt((alpha ** 2) * (num_st + kappa)) # UKF scaling factor
sqrt_sc = tf.scalar_mul(eta, sqrt_cov) # Scaled square-root
sig = np.matlib.repmat(x_prev, 1, 2*num_st+1)
sig[:, 1:num_st+1] = sig[:, 1:num_st+1] + sqrt_sc
sig[:, num_st+1:2*num_st+1] = sig[:, num_st+1:2*num_st+1] - sqrt_sc # Sigma points## Inputs: Sigma Point Matrix - sig, UKF Weights - w0_mean, w0_cov, wi, # States - num_st, Process covariance - Q
## Outputs: Predicted State Vector - x_minus, Predicted Covariance - cov_minus
x_minus = w0_mean * sig[:, 0] + w_i * tf.reduce_sum(sig[:, 1:2 * num_st + 1], axis=1)
x_minus = tf.reshape(x_minus, (num_st, 1))
temp1 = tf.reshape(sig[:, 0], (num_st, 1))
# Predict Covariance
cov_minus = w0_cov * (temp1 - x_minus) * tf.transpose((temp1 - x_minus))
for i in range(1, 2 * num_st + 1):
temp1 = tf.reshape(sig[:, i], (num_st, 1))
cov_minus = cov_minus + w_i * (temp1 - x_minus) * tf.transpose((temp1 - x_minus))
cov_minus = cov_minus + Q## Inputs: Sigma Point Matrix - sig, Current Crack Size - init_crack, Stress Constant - dsig,
## Cycles Interval - diff_cycles, # States - num_st
## Output: Output Matrix - gam
gam = np.zeros((1, 2*num_st+1))
for indx in range(0, 2*num_st+1):
logC = sig[0, indx]
m = sig[1, indx]
gam[:, indx] = predict_crack(diff_cycles, logC, m, init_crack, dsig)## Inputs: Output Matrix - gam, Sigma Point Matrix - sig, State Vector - x_prev, UKF Parameters - w0_mean, w0_cov, wi,
## # States - num_st, Measurement Covariance - R
## Outputs: Cross Covariance - cov_xy, Output Covariance - cov_yy, Output Vector - yhat
yhat = w0_mean * gam[:, 0] + w_i * tf.reduce_sum(gam[:, 1:2 * num_st + 1]) # Output vector
temp2 = tf.reshape(sig[:, 0], (num_st, 1))
cov_yy = w0_cov * (gam[:, 0] - yhat) * tf.transpose(gam[:, 0] - yhat) # Output covariance
cov_xy = w0_cov * (temp2 - x_prev) * tf.transpose(gam[:, 0] - yhat) # Cross covariance
for i in range(1, 2*num_st+1):
temp2 = tf.reshape(sig[:, i], (num_st, 1))
cov_yy = cov_yy + w_i * (gam[:, i] - yhat) * tf.transpose(gam[:, i] - yhat)
cov_xy = cov_xy + w_i * (temp2 - x_prev) * tf.transpose(gam[:, i] - yhat)
cov_yy = (cov_yy + tf.transpose(cov_yy))/2 # Ensure symmetry
cov_yy = cov_yy + R## Inputs : Predicted State Vector - x_minus, Predicted State Covariance - cov_minus, Predicted Output - yhat,
# Measured Output - y, Output Covariance cov_yy, Cross Covariance - cov_xy
## Outputs: Updated State Vector - x_hat, Updated State Covariance - cov_hat
k_gain = cov_xy * np.linalg.inv(np.matrix(cov_yy)) # calculate filter gain
innov = y - y_hat # innovation
x_hat = x_minus + k_gain * innov # update state
cov_hat = cov_minus - k_gain * cov_yy * tf.transpose(k_gain) # update covariance
cov_hat = (cov_hat + tf.transpose(cov_hat)) / 2 # ensure symmetry 可以观察到,与初始模型相比,更新后的模型预测更准确。但这只是一个显而易见的结果,因为我们正在对用于更新模型的同一数据集进行预测。只有在使用未用于更新的数据集验证更新后的模型预测时,才能真正衡量更新后的模型的准确性。更重要的是,更新后的模型在预测裂纹的未来演变方面应该比初始模型更准确。否则,即使更新后的模型也并不特别有用。
可以观察到,与初始模型相比,更新后的模型预测更准确。但这只是一个显而易见的结果,因为我们正在对用于更新模型的同一数据集进行预测。只有在使用未用于更新的数据集验证更新后的模型预测时,才能真正衡量更新后的模型的准确性。更重要的是,更新后的模型在预测裂纹的未来演变方面应该比初始模型更准确。否则,即使更新后的模型也并不特别有用。 基于 UKF 的模型更新方法不仅估计模型参数的均值,还计算与估计相关的协方差。换句话说,它提供了状态变量的联合分布。TensorFlow Probability 的
基于 UKF 的模型更新方法不仅估计模型参数的均值,还计算与估计相关的协方差。换句话说,它提供了状态变量的联合分布。TensorFlow Probability 的 MultivariateNormalFullCovariance 函数用于创建样本,以计算与预测输出(在本例中为裂纹尺寸)相关的 uncertainty。预测裂纹尺寸的 95% 可信区间也绘制在上面的图形中。从图中可以清楚地看出,与初始模型相比,更新后的模型在预测裂纹的未来演变方面明显更准确。这表明 UKF 能够从更新数据集中的测量值中提取相关信息,以修改模型参数,使模型更准确、更有用。这里要提到的另一个重要事项是这种方法对噪声测量的鲁棒性。在更新数据集中,对应于循环 600 和 700 的测量值与其他测量的裂纹值相比是异常值。但是,这些异常值对模型更新过程的影响相当小,因为 UKF 没有尝试最小化这些数据点上的预测和观察之间的误差。这是一个理想的结果,这种对噪声测量的鲁棒性对于获得准确的更新模型至关重要。
最后,我们使用初始模型和更新后的模型预测裂纹尺寸到 2200 个循环。预测结果以及更新后的模型的 uncertainty 边界如下所示。
 从上面的图表中可以明显看出,如果使用初始模型,裂纹预测将非常不准确。实际上,初始模型将在 2100 个循环时产生错误警报,而此时发现大于修复阈值的裂纹的真实概率非常小(<< 5%)。
从上面的图表中可以明显看出,如果使用初始模型,裂纹预测将非常不准确。实际上,初始模型将在 2100 个循环时产生错误警报,而此时发现大于修复阈值的裂纹的真实概率非常小(<< 5%)。

2018 年 12 月 18 日 — 由 Venkatesh Rajagopalan(数据科学与分析总监)和 Arun Subramaniyan(BHGE Digital 数据科学与分析副总裁)发布
在本系列的 第一篇博客 中,我们介绍了我们的分析理念,即结合领域知识、概率方法、传统机器学习 (ML) 和深度学习技术来解决工业领域中一些最棘手的问题。我们还…





