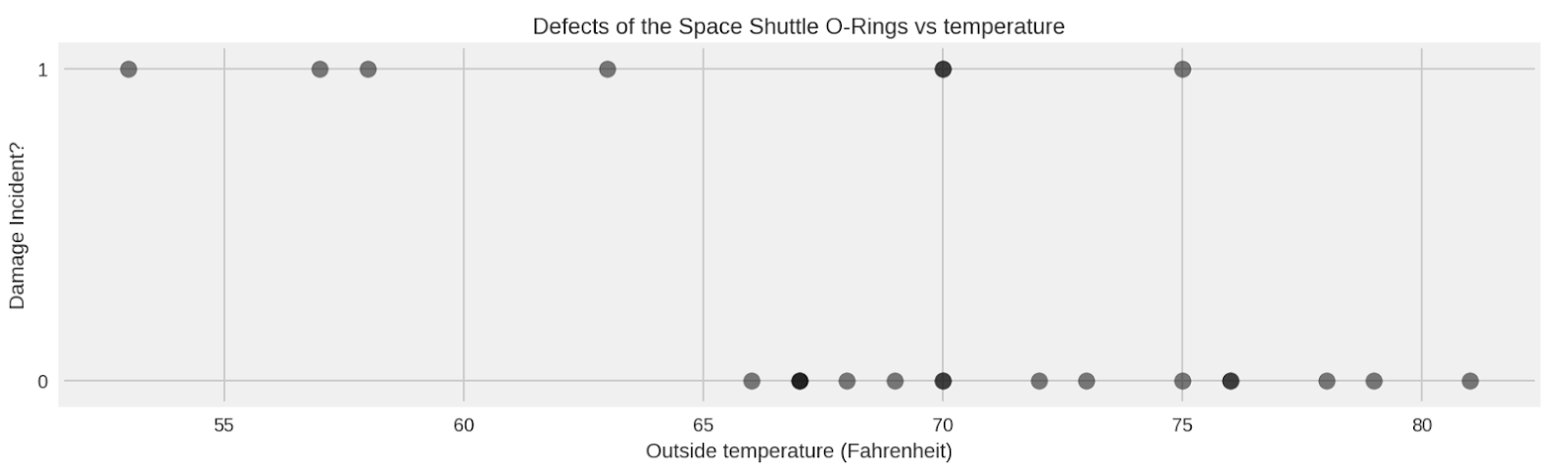

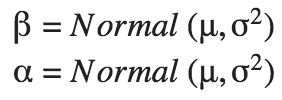
tfp.distributions.Normal 来表示 α 和 β,如以下代码片段所示temperature_ = challenger_data_[:, 0]
temperature = tf.convert_to_tensor(temperature_, dtype=tf.float32)
D_ = challenger_data_[:, 1] # defect or not?
D = tf.convert_to_tensor(D_, dtype=tf.float32)
beta = tfd.Normal(name="beta", loc=0.3, scale=1000.).sample()
alpha = tfd.Normal(name="alpha", loc=-15., scale=1000.).sample()
p_deterministic = tfd.Deterministic(name="p", loc=1.0/(1. + tf.exp(beta * temperature_ + alpha))).sample()
[
prior_alpha_,
prior_beta_,
p_deterministic_,
D_,
] = evaluate([
alpha,
beta,
p_deterministic,
D,
])evaluate() 辅助函数允许我们在图形模式和急切模式之间无缝切换,同时将张量值转换为 numpy。我们在 第 2 章 的开头更详细地描述了急切模式和图形模式以及此辅助函数。
joint_log_prob 的参数是数据和模型状态。该函数返回参数化模型生成观测数据的联合概率的对数。要详细了解 joint_log_prob,请参阅 此说明。joint_log_probdef challenger_joint_log_prob(D, temperature_, alpha, beta):
"""
Joint log probability optimization function.
Args:
D: The Data from the challenger disaster representing presence or
absence of defect
temperature_: The Data from the challenger disaster, specifically the temperature on
the days of the observation of the presence or absence of a defect
alpha: one of the inputs of the HMC
beta: one of the inputs of the HMC
Returns:
Joint log probability optimization function.
"""
rv_alpha = tfd.Normal(loc=0., scale=1000.)
rv_beta = tfd.Normal(loc=0., scale=1000.)
logistic_p = 1.0/(1. + tf.exp(beta * tf.to_float(temperature_) + alpha))
rv_observed = tfd.Bernoulli(probs=logistic_p)
return (
rv_alpha.log_prob(alpha)
+ rv_beta.log_prob(beta)
+ tf.reduce_sum(rv_observed.log_prob(D))
)rv_alpha 和 rv_beta 代表我们对 α 和 β 的先验分布的随机变量。相比之下,rv_observed 代表给定由 α 和 β 参数化的逻辑分布时,温度和 O 形圈结果中观测结果的似然的条件分布。joint_log_prob 函数发送到 tfp.mcmc 模块。马尔可夫链蒙特卡洛 (MCMC) 算法对未知输入值进行有根据的猜测,计算 joint_log_prob 函数中参数集的可能性。通过多次重复此过程,MCMC 构建了可能参数的分布。构建此分布是概率推理的目标。challenge_joint_log_prob 函数上number_of_steps = 10000
burnin = 2000
# Set the chain's start state.
initial_chain_state = [
0. * tf.ones([], dtype=tf.float32, name="init_alpha"),
0. * tf.ones([], dtype=tf.float32, name="init_beta")
]
# Since HMC operates over unconstrained space, we need to transform the
# samples so they live in real-space.
# Alpha is 100x of beta approximately, so apply Affine scalar bijector
# to multiply the unconstrained alpha by 100 to get back to
# the Challenger problem space
unconstraining_bijectors = [
tfp.bijectors.AffineScalar(100.),
tfp.bijectors.Identity()
]
# Define a closure over our joint_log_prob.
unnormalized_posterior_log_prob = lambda *args: challenger_joint_log_prob(D, temperature_, *args)
# Initialize the step_size. (It will be automatically adapted.)
with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE):
step_size = tf.get_variable(
name='step_size',
initializer=tf.constant(0.5, dtype=tf.float32),
trainable=False,
use_resource=True
)
# Defining the HMC
hmc=tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
num_leapfrog_steps=40, #to improve convergence
step_size=step_size,
step_size_update_fn=tfp.mcmc.make_simple_step_size_update_policy(
num_adaptation_steps=int(burnin * 0.8)),
state_gradients_are_stopped=True),
bijector=unconstraining_bijectors)
# Sampling from the chain.
[
posterior_alpha,
posterior_beta
], kernel_results = tfp.mcmc.sample_chain(
num_results = number_of_steps,
num_burnin_steps = burnin,
current_state=initial_chain_state,
kernel=hmc)
# Initialize any created variables for preconditions
init_g = tf.global_variables_initializer()evaluate() 辅助函数实际执行推理evaluate(init_g)
[
posterior_alpha_,
posterior_beta_,
kernel_results_
] = evaluate([
posterior_alpha,
posterior_beta,
kernel_results
])
print("acceptance rate: {}".format(
kernel_results_.inner_results.is_accepted.mean()))
print("final step size: {}".format(
kernel_results_.inner_results.extra.step_size_assign[-100:].mean()))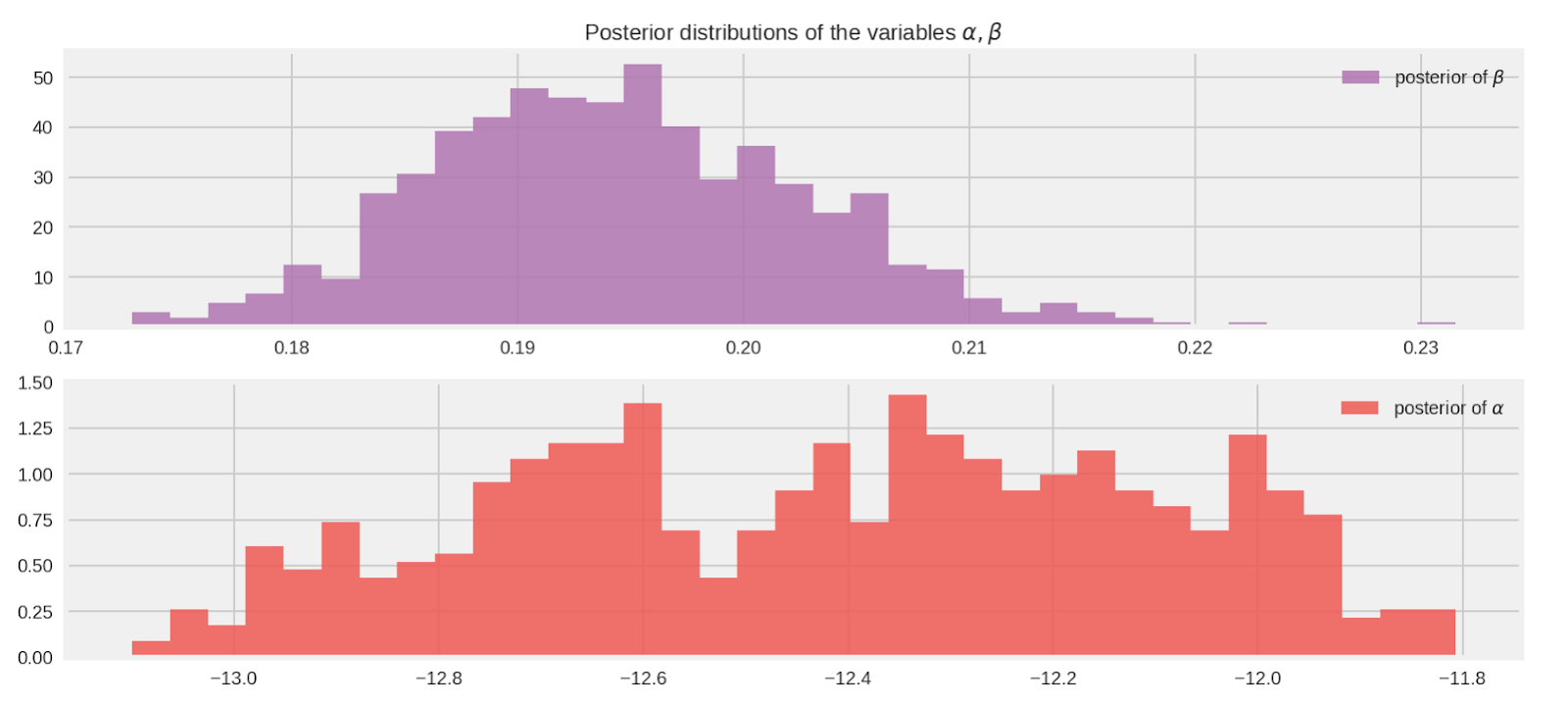
alpha_samples_1d_ = posterior_alpha_[:, None] # best to make them 1d
beta_samples_1d_ = posterior_beta_[:, None]
beta_mean = tf.reduce_mean(beta_samples_1d_.T[0])
alpha_mean = tf.reduce_mean(alpha_samples_1d_.T[0])
[ beta_mean_, alpha_mean_ ] = evaluate([ beta_mean, alpha_mean ])
print("beta mean:", beta_mean_)
print("alpha mean:", alpha_mean_)
def logistic(x, beta, alpha=0):
"""
Logistic function with alpha and beta.
Args:
x: independent variable
beta: beta term
alpha: alpha term
Returns:
Logistic function
"""
return 1.0 / (1.0 + tf.exp((beta * x) + alpha))
t_ = np.linspace(temperature_.min() - 5, temperature_.max() + 5, 2500)[:, None]
p_t = logistic(t_.T, beta_samples_1d_, alpha_samples_1d_)
mean_prob_t = logistic(t_.T, beta_mean_, alpha_mean_)
[
p_t_, mean_prob_t_
] = evaluate([
p_t, mean_prob_t
])


2018 年 12 月 10 日 — 由 Google TensorFlow Probability 产品经理Mike Shwe;Google TensorFlow Probability 软件工程师 Josh Dillon;Google 软件工程师 Bryan Seybold;Matthew McAteer;和Cam Davidson-Pilon 撰写。
概率编程新手?TensorFlow Probability (TFP) 新手?那么我们有一款适合您的产品。贝叶斯方法黑客指南,一个入门级的动手教程,…





