import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
from sklearn.preprocessing import MultiLabelBinarizer!wget 'https://storage.googleapis.com/movies_data/movies_metadata.csv'
data = pd.read_csv('movies_metadata.csv')
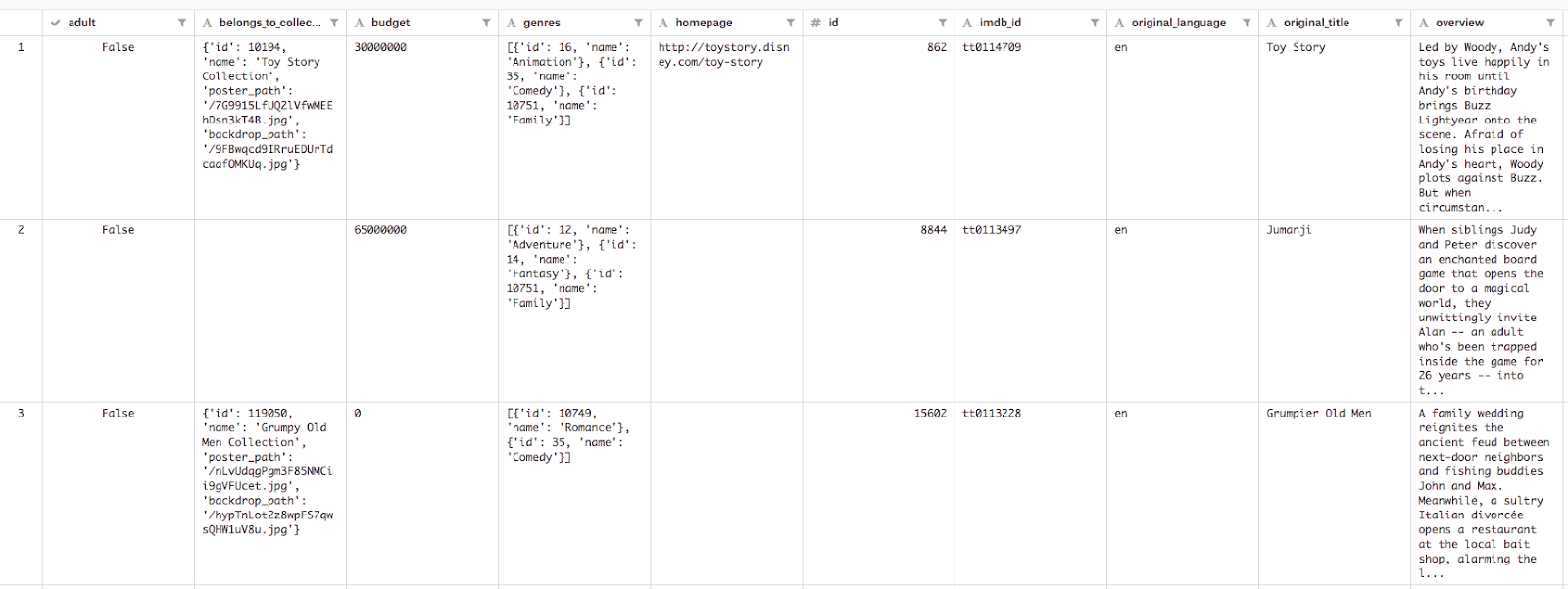
descriptions = data['overview']
genres = data['genres']top_genres = ['Comedy', 'Thriller', 'Romance', 'Action', 'Horror', 'Crime', 'Documentary', 'Adventure', 'Science Fiction']train_size = int(len(descriptions) * .8)
train_descriptions = descriptions[:train_size]
train_genres = genres[:train_size]
test_descriptions = descriptions[train_size:]
test_genres = genres[train_size:]hub.text_embedding_column 在一行代码中为这一层创建一个特征列,并将我们的层的名称(“movie_descriptions”)和我们将使用的 TF Hub 模型的 URL 传递给它description_embeddings = hub.text_embedding_column(
"movie_descriptions",
module_spec="https://tfhub.dev/google/universal-sentence-encoder/2"
)['Action', 'Adventure'])。由于每个标签都需要相同长度,因此我们将这些列表转换为 1 和 0 的多热向量,对应于特定描述中存在的类型。动作和冒险电影的多热向量将如下所示# Genre lookup, each genre corresponds to an index
top_genres = ['Comedy', 'Thriller', 'Romance', 'Action', 'Horror', 'Crime', 'Documentary', 'Adventure', 'Science Fiction']
# Multi-hot label for an action and adventure movie
[0 0 0 1 0 0 0 1 0]MultiLabelBinarizer 的 scikit learn 实用程序encoder = MultiLabelBinarizer()
encoder.fit_transform(train_genres)
train_encoded = encoder.transform(train_genres)
test_encoded = encoder.transform(test_genres)
num_classes = len(encoder.classes_)encoder.classes_ 以查看模型预测的所有字符串类的列表。head,它定义了模型应期望的标签类型。由于我们希望我们的模型输出多个标签,因此我们将在这里使用 multi_label_headmulti_label_head = tf.contrib.estimator.multi_label_head(
num_classes,
loss_reduction=tf.losses.Reduction.SUM_OVER_BATCH_SIZE
)DNNEstimator 时将其传递进来。hidden_units 参数指示网络中将有多少层。此模型有 2 层,第一层有 64 个神经元,第二层有 10 个神经元。层数和层大小是一个超参数,因此您应该尝试不同的值以查看哪个值最适合您的数据集。最后,我们将特征列传递给 Estimator。在本例中,我们只有一个(描述),并且我们已经在上面将其定义为 TF Hub 嵌入列,因此我们可以将其作为列表传递到这里estimator = tf.contrib.estimator.DNNEstimator(
head=multi_label_head,
hidden_units=[64,10],
feature_columns=[description_embeddings]
)numpy_input_fn 并将我们的数据作为 numpy 数组馈送到我们的模型# Format our data for the numpy_input_fn
features = {
"descriptions": np.array(train_descriptions)
}
labels = np.array(train_encoded)
train_input_fn = tf.estimator.inputs.numpy_input_fn(
features,
labels,
shuffle=True,
batch_size=32,
num_epochs=20
)batch_size 和 num_epochs 参数都是超参数。batch_size 告诉我们的模型在一次迭代期间将多少个示例传递到我们的模型,而 num_epochs 是我们的模型遍历整个训练集的次数。estimator.train(input_fn=train_input_fn)estimator.evaluate()eval_input_fn = tf.estimator.inputs.numpy_input_fn({"descriptions": np.array(test_descriptions).astype(np.str)}, test_encoded.astype(np.int32), shuffle=False)
estimator.evaluate(input_fn=eval_input_fn)raw_test = [
"An examination of our dietary choices and the food we put in our bodies. Based on Jonathan Safran Foer's memoir.", # Documentary
"A teenager tries to survive the last week of her disastrous eighth-grade year before leaving to start high school.", # Comedy
"Ethan Hunt and his IMF team, along with some familiar allies, race against time after a mission gone wrong." # Action, Adventure
]predict()predict_input_fn = tf.estimator.inputs.numpy_input_fn({"descriptions": np.array(raw_test).astype(np.str)}, shuffle=False)
results = estimator.predict(predict_input_fn)for movie_genres in results:
top_2 = movie_genres['probabilities'].argsort()[-2:][::-1]
for genre in top_2:
text_genre = encoder.classes_[genre]
print(text_genre + ': ' + str(round(movie_genres['probabilities'][genre] * 100, 2)) + '%')
2018 年 8 月 15 日 - 作者:开发者布道师 Sara Robinson
我们经常看到迁移学习应用于计算机视觉模型,但对于文本分类呢?进入 TensorFlow Hub,一个用于通过迁移学习增强您的 TF 模型的库。迁移学习是指使用已经过大量数据训练的预先存在的模型的权重和变量,并将其用于您自己的数据和预测任务的过程。...





